... und mit einer Hashmap |
|
|
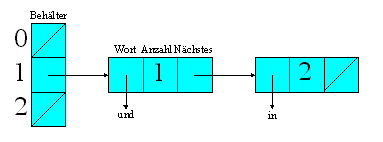
Um die Wörter eines Textes schneller zu zählen, kann man
sich eine eigene Hashmap erstellen. Hier enthält jeder Knoten
eine Zeiger auf ein Wort, die Häufigkeit des Auftretens in dem
Text und einen Zeiger auf den nächsten Knoten in der Hashmap. Das
folgende Beispiel zeigt, wie die Hashmap aussieht, für den Fall,
daß einmal das Wort 'und' und zweimal das Wort 'in' eingefügt
worden sind. Die Wörter haben in diesem Beispiel den gleichen
Hashwert. |
|
 |
|
Die C-Struktur stellt nur die nötigsten Angaben für die Hashtabelle bereit. Das ist ein Zeiger auf des Wort, die Auftrittshäufigkeit und einen Zeiger auf den nächsten Knoten. |
|
Die Hashfunktion ordnet jedem Wort eine postive Zahl größer als NHASH zu. NHASH gibt die Größe der Hashtabelle an. Idealerweise ist dies eine Primzahl, die etwas größer ist, als die Anzahl der verschiedenen Wörter, die in dem Text auftreten. |
|
Diese Funktion leistet eigentlich den größten Teil der Arbeit. Sie läßt zuerst den Hashwert des Wortes berechnen. Dann wird jedes Wort, daß den gleichen Hashwert besitzt mit der Eingabe verglichen. Falls das Wort schon in der Hashtabelle enthalten sein sollte, wird einfach der Zähler erhöht. Gibt es noch keine Knoten für diese Wort, dann wird ein neuer erstellt, Speicherplatz bereitgestellt, eine Kopie des Wortes angelegt und schließlich am Anfang der Liste eingefügt. |
|
Die main()-Funktion stellt sicher, daß die Hashtabelle noch nicht gefüllt ist. Sie liest dann die Eingabe ein und übergibt sie an die Funktion incword(). Am Ende wird die Ausgabe bereitgestellt. |
|
|
Die Erstellung der Wortliste dauert nur noch ca. 1.22 Sekunden. (0.80 lesen, 0.33 einfügen, 0.09 schreiben) und ist somit ca. 7.77 Sekunden schneller. |